
Industrial big data and artificial intelligence are propelling a new era of manufacturing, smart manufacturing. Although these driving technologies have the capacity to advance the state of the art in manufacturing, it is not trivial to do so. Current benchmarks of quality, conformance, productivity, and innovation in industrial manufacturing have set a very high bar for machine learning algorithms. A new concept has recently appeared to address this challenge: Quality 4.0. This name was derived from the pursuit of performance excellence during these times of potentially disruptive digital transformation. The hype surrounding artificial intelligence has influenced many quality leaders take an interest in deploying a Quality 4.0 initiative. According to recent surveys, however, 80–87% of the big data projects never generate a sustainable solution. Moreover, surveys have indicated that most quality leaders do not have a clear vision about how to create value of out these technologies. In this manuscript, the process monitoring for quality initiative, Quality 4.0, is reviewed. Then four relevant issues are identified (paradigm, project selection, process redesign and relearning problems) that must be understood and addressed for successful implementation. Based on this study, a novel 7-step problem solving strategy is introduced. The proposed strategy increases the likelihood of successfully deploying this Quality 4.0 initiative.

Avoid common mistakes on your manuscript.
Manufacturing is a primary economic driving force. Modern manufacturing began with the introduction of the factory system in late eighteenth century Britain. This precipitated the first industrial revolution (mechanical production) and later spread worldwide. The defining feature of the first factory system was the use of machinery, initially powered foot treadles, soon after by water or steam and later by electricity. The second industrial revolution (science and mass production) was a phase of electrification, rapid standardization, and production lines, spanning from the late nineteenth to the early twentieth century. The introduction of the internet, automation, telecommunications, and renewable energies in the late twentieth and early in the twenty-first century gave rise to the third industrial revolution (globalization and digital revolution) [1].
Today, at the brink of the fourth industrial revolution (interconnectedness, data and intelligence) or Industry 4.0 [2], technologies such as Industrial Big Data (IBD) [3], Industrial Internet of Things (IIoT) [4], acsensorization [5], Artificial Intelligence (AI) [6], and Cyber-Physical Systems (CPS) [2] are propelling the new era of manufacturing, smart manufacturing [7]. Mass customization, just-in-time maintenance, solutions to engineering intractable problems, disruptive innovation, and perfect quality are among the most relevant challenges posed to this revolution. Manufacturing systems are upgraded to an intellectual level that leverages advanced manufacturing and information technologies to achieve flexible, intelligent, and reconfigurable manufacturing processes to address a dynamic, global marketplace. Some technologies also have AI, which allows manufacturing systems to learn from experiences to realize a connected, intelligent, and ubiquitous industrial practice [8].
Although the driving technologies in the fourth industrial revolution have the capacity to move the state of the art in manufacturing forward, it is not trivial to do so. Current benchmarks of quality, productivity, and innovation in industrial manufacturing are very high. Rapid innovation shorten process lifespans, leaving little time to understand and solve engineering problems from a physics perspective. Moreover, application of Statistical Quality Control (SQC) techniques have enabled most modern processes to yield very low Defects per Million of Opportunities (DPMO) (6 \(\sigma \) , 3.4 DPMO). This ultra-high conformance rate sets a very high bar for AI. These challenges will only intensify, since smart manufacturing is driven by processes that exhibit increasing complexity, short cycle times, transient sources of variation, hyper-dimensional feature spaces, as well as non-Gaussian pseudo-chaotic behavior.
To address this in the age of the fourth industrial revolution, a new concept has recently appeared: Quality 4.0. This name was derived from the pursuit of performance excellence during these times of potentially disruptive digital transformation [9].
The authors define Quality 4.0 as:
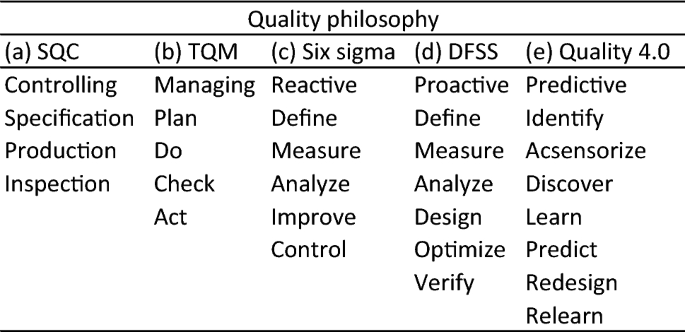
Quality 4.0 is the fourth wave in the quality movement (1.Statistical Quality Control, 2.Total Quality Management, 3.Six sigma, 4.Quality 4.0). This quality philosophy is built on the statistical and managerial foundations of the previous philosophies. It leverages industrial big data, industrial internet of things, and artificial intelligence to solve an entirely new range of intractable engineering problems. Quality 4.0 is founded on a new paradigm based on empirical learning, empirical knowledge discovery, and real-time data generation, collection, and analysis to enable smart decisions.
In manufacturing, the main objectives of Quality 4.0 are: (1) to develop defect-free processes, (2) to augment human intelligence, such as empirical knowledge discovery for faster root cause analyses, (3) to increase the speed and quality of decision-making, and (4) to alleviate the subjective nature of human-based inspection [9,10,11]. According to recent surveys, although 92% of surveyed leaders are increasing their investments in IBD and AI [12], a substantial portion of these quality leaders do not yet have a deployment strategy [11] and universally cite difficulty in harnessing these technologies [13]. This situation is reflected in the deployment success rate: 80–87% of the big data projects never generate a sustainable solution [14, 15].
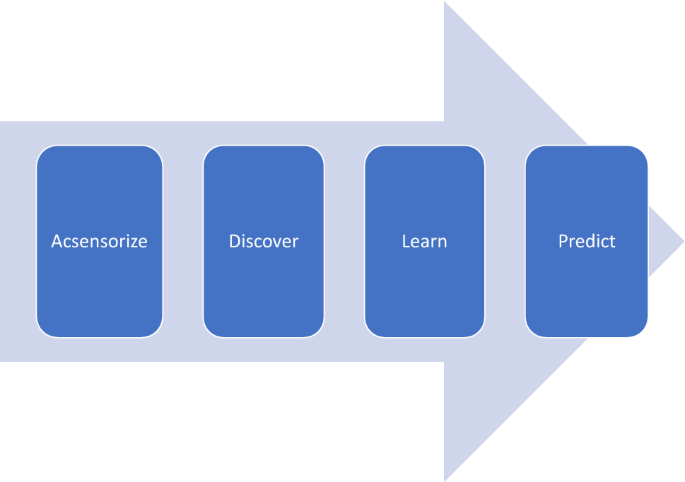
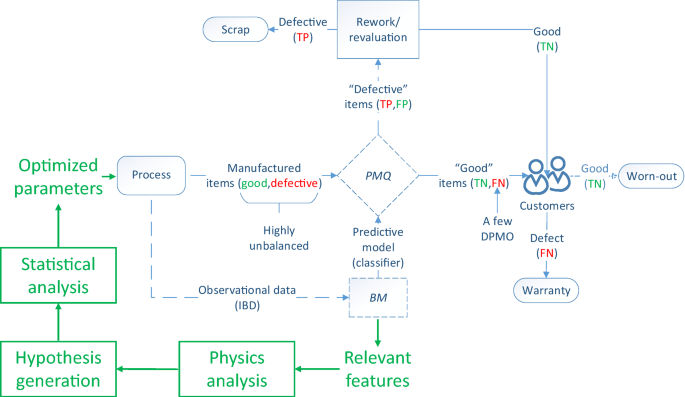
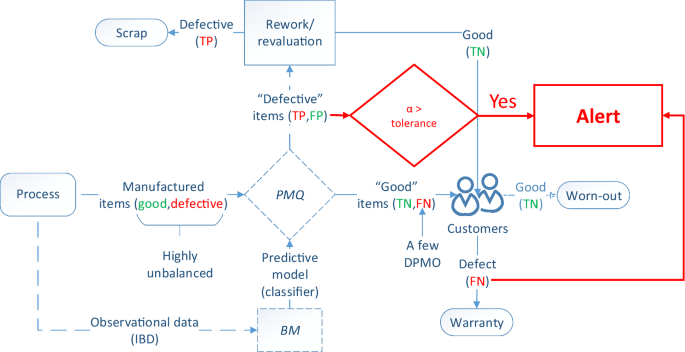
Process Monitoring for Quality (PMQ) [5] is a data-driven quality philosophy aimed at addressing the intellectual and practical challenges posed to the application of AI in manufacturing. It is founded on Big Models (BM) [16], a predictive modeling paradigm that applies machine learning, statistics, and optimization to process data to develop a classifier aimed at real-time defect detection and empirical knowledge discovery aimed at process redesign and improvement. To effectively solve the pattern classification problem, PMQ proposes a 4-step approach—acsensorize, discover, learn, predict (ADLP). Figure 1 describes the PMQ Quality 4.0 initiative in the context of Industry 4.0.

In this review, four relevant-to-manufacturing issues are identified that quality and manufacturing engineers/researchers, managers, and directors must understand and address to successfully implement a Quality 4.0 initiative based on PMQ: (1) the paradigm problem, (2) project selection problem, (3) process redesign problem, and (4) relearning problem. Based on this study, the original PMQ 4-step problem solving strategy is revised and enhanced to develop a comprehensive approach that increases the likelihood of success. This novel strategy is an evolution of the Shewhart learning and improvement cycle (widely used in manufacturing for quality control) to address the challenges posed to the implementation of this Quality 4.0 initiative.
This paper does not attempt to offer new methods, algorithms or techniques. The agenda of the problem solving strategy is pragmatic: defect detection through binary classification and empirical knowledge discovery that can be used for process redesign and improvement. Its scope is limited to discrete manufacturing systems, where a deterministic solution for process monitoring and control is not available or feasible.
The rest of the paper is organized as follows: a review of the state of the art in “Similar work” section. A brief description of PMQ in “PMQ and its applications” section. The four problems are discussed in “Challenges of big data initiatives in manufacturing” section. Then, the PMQ 4-step problem solving strategy is updated in “Problem solving strategy for a Quality 4.0 initiative” section. An implementation strategy is presented in “Strategy development and adoption for Quality 4.0” section. Finally, conclusions and future research are contained in “Conclusions” section.
Manufacturing has been a primary economic driving force since the first industrial revolution in the nineteenth century and continues to be so today. The Industry 4.0 paradigm has necessitated a similar paradigm shift in manufacturing to keep up with quick launch, low volume production, and mass customization of products [17], all while conforming to high quality and productivity requirements. This new manufacturing paradigm has been termed smart manufacturing, and it has been enabled by technologies such as IIoT, CPS, cloud computing [18], Big Data Analytics, Information and Communications Technology, and AI [8]. IBD offers an excellent opportunity to enable the shift from conventional manufacturing to smart manufacturing. Companies now have the option of adopting data-driven strategies to provide a competitive advantage.
In 2017, Kusiak [19] advocated for manufacturing industries to embrace and employ the concepts of Big Data Analytics in order to increase efficiency and profits. Tao et al. [20] studied big data’s role in supporting this transition to smart manufacturing. Fisher et al. [21] investigated how models generated from the data can characterize process flows and support the implementation of circular economy principles and potential waste recovery.
Though smart manufacturing has taken off in more recent years, the concept has been around for decades. In 1990, Kusiak [22] authored Intelligent Manufacturing Systems, which was designed to provide readers with a reference text on such systems. For a more recent reviews, the reader is referred to [23, 24]. The wealth of data has both contributed to and enabled the rise of smart manufacturing practices. In 2009, Choudhary et al. [25] provided a detailed literature review on data mining and knowledge discovery in various manufacturing domains. More recently (2020), Cheng et al. [26] proposed data mining technique to enhance training dataset construction to improve the speed and accuracy of makespan estimation. Wei et al. [27] proposed a data analysis-driven process design method based on data mining, a data + knowledge + decision backward design pattern, to enhance manufacturing data.
Quality is a fundamental business imperative for manufacturing industries. Historically, i.e., pre-Industry 4.0, manufacturing industries have produced higher volumes for products with longer intended lifecycles. Consequently, there was more time and data on which to refine processes and reduce process variance. In other words, there was a longer learning curve to enable the production of high-quality products. In the era of smart manufacturing, the luxury of these long learning curves is removed. This has propelled the adoption of intelligent process monitoring and product inspection techniques. Some examples of these Quality 4.0 applications will now be presented.
In 2014, Wuest et al. [28] introduced a manufacturing quality monitoring approach in which they applied cluster analysis and supervised learning on product state data to enable monitoring of highly complex manufacturing processes. Malaca et al. [29] designed a system to enable the real-time classification of automotive fabric textures in low lighting conditions. In 2020, Xu and Zhu [30] used the concept of fog computing to design a classification system in order to identify potential flawed products within the production process. Cai et al. [31] proposed a hybrid information system based on an artificial neural network of short-term memory to predict or estimate wear and tear on manufacturing tools. Their results showed outstanding performance for different operating conditions. Said et al. [32] proposed a new method for machine learning flaw detection using the reduced kernel partial least squares method to handle non-linear dynamic systems. Their research resulted in a calculation time reduction and a decrease in the rate of false alarms. Hui et al. [33] designed data-based modeling to assess the quality of a linear axis assembly based on normalized information and random sampling. They used the replacement variable selection method, synthetic minority oversampling technique, and optimized multi-class Support Vector Machine.
The cases briefly presented include fault detection systems, classifiers development techniques, or process control systems. The common denominator is that they are all data-driven approaches based on artificial intelligence algorithms. In most cases, a particular problem is solved. Therefore, unless managers or directors have a similar problem, they cannot develop a high impact Quality 4.0 initiative from what is reported. In this context, this article highlights several manufacturing issues that must be understood and addressed to successfully deploy a Quality 4.0 initiative across manufacturing plants.
Though quality inspections are widely practiced before, during, and after production, these inspections still highly rely on human capabilities. According to a recent survey, almost half of the respondents claimed that their inspections were mostly manual (i.e., less than 10% automated) [34]. Manual or visual inspections are often subject to the operators’ inherent biases, and thus only about 80% accurate [35]. This generates the hidden factory effect, where unforeseen activities contribute to efficiency and quality reduction [36]. PMQ proposes to use real-time process data to automatically monitor and control the processes, i.e., identify and eliminate defects. Where defect detection is formulated as a binary classification problem. PMQ originally proposed a 4-step problem solving strategy, Fig. 2:
The confusion matrix is a table used to summarize the predictive ability of a classifier, Table 1. Where a positive result refers to a defective item, and a negative result refers to a good quality item. Since prediction is performed under uncertainty, a classifier can commit FP (type-I, \(\alpha \) ) and FN (type-II, \(\beta \) ) errors [41].
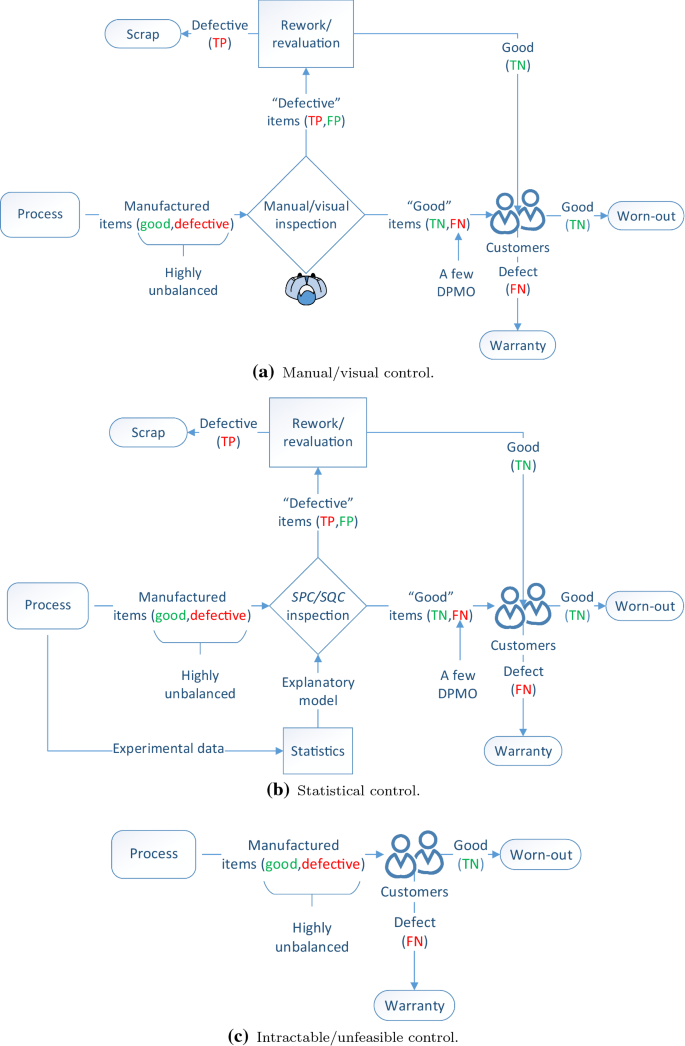
The processes of most mature manufacturing organizations generate only a few defective items, Fig. 3. The majority of these defects are detected (TP) by either a manual/visual inspection, Fig. 3a or by a statistical process monitoring system (SPC/SQC), Fig. 3b. Detected defects are removed from the value-adding process for a second evaluation, where they are finally either reworked or scrapped. Since neither inspection approaches are 100% reliable[35, 43], they can commit FP (i.e., call a good item defective) and FN (i.e., call a defective item good) errors. Whereas FP create the hidden factory effect by reducing the efficiency of the process, FN should always be avoided as they cause warranties.
In extreme cases, Fig. 3c, time-to-market pressures may compel a new process to be developed and launched even before it is totally understood from physics perspective. Even if a new SPC/SQC model/system is developed or a pre-existing model or system is used, it may not be feasible to measure its quality characteristics (variables) within the time constraints of the cycle time. In these intractable or infeasible cases, the product is launched at a high risk for the manufacturing company.
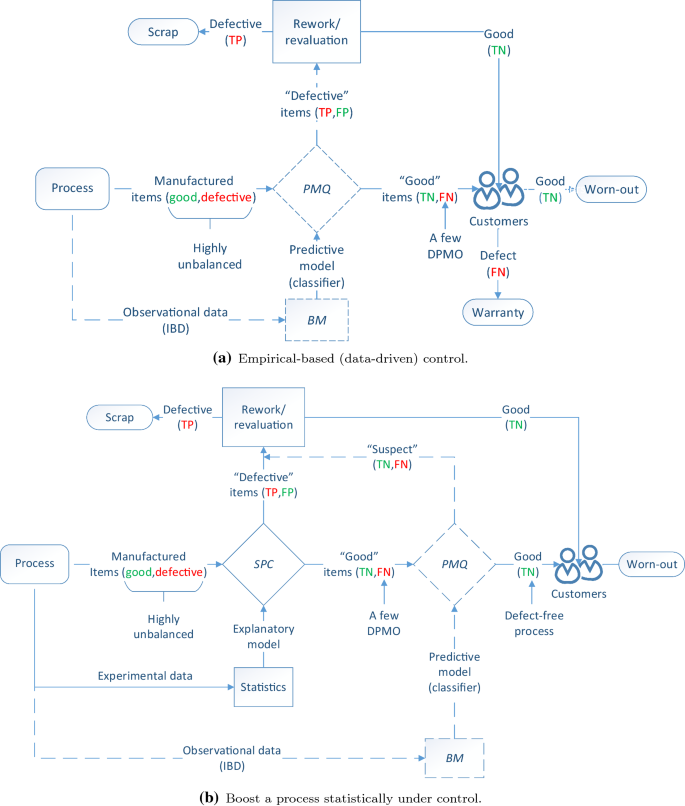
PMQ is applied to eliminate manual or visual inspections, as well as to develop an empirical-based quality control system for the intractable and unfeasible cases, Fig. 4a. The real case of ultrasonic welding of battery tabs in the Chevrolet Volt is a good example of this approach [5]. In a process statistically under control, PMQ can also be applied to detect those few DPMO (FN) not detected by the SPC/SQC system to enable the creation of virtually defect-free processes through perfect detection [10], Fig. 4b. Finally, the empirical knowledge discovery component-aimed at process redesign and improvement-of PMQ is described in “The redesign problem” section.
From the initiative of implementing Quality 4.0 in the plants, to actually develop and deploy a sustainable solution (i.e., predictive system) that would endure the dynamism of manufacturing systems, a plethora of managerial, intellectual, technical, and practical challenges must be effectively addressed. Manufacturing knowledge and a solid learning strategy must therefore be in place to avoid painful lessons characterized by over-promises and under-deliveries.
Although the intention of this paper is not to train data scientists in machine learning techniques (this task may take months or even years), this section provides an overview of the most relevant challenges posed by the development of a binary classifier using manufacturing-derived data and suggests a direction to address these challenges. This subsection aims to contextualize and provide some background for the next section.
In Quality 4.0, process data is generated, collected and analyzed real-time. Developing the real-time infrastructure is one of the last steps of the project and is usually addressed at the deployment stage. Proof-of-concepts are based on asynchronous analyses, as the first challenge for the data scientists is to demonstrate feasibility.
Prior to developing a model, the training data is generated or collected; each sample must have the associated quality characteristic (good, defective) for the algorithm to learn the pattern. In general, there are two common cases: (1) plant data and (2) lab-generated data. When available, plant data is the most desirable since it is a representative, relevant environment, data-rich option in which the process is already observed (i.e., data generated and stored). This allows for feasibility assessment to be performed promptly. Lab-generated data aims to imitate relevant environmental conditions and is usually limited to smaller data sets. The principle of acsesorization describes good insights about exploring different options for data generation [5].
The process data is usually found in three common formats: (1) pictures, (2) signals, and (3) direct measurements of quality characteristics (features). For the first two formats, features can be created following typical construction techniques [38, 39, 44]. Feature creation followed by a feature relevance analysis helps engineers to determine the driving features of the system, information further used for deriving physics knowledge and augment troubleshooting. This concept is explained in more detail in the following section. Raw signals and images can also be used to train a deep neural network architecture for quality control [45, 46]. Although these black boxes can efficiently solve many engineering problems from a prediction perspective, they do not facilitate information extraction. More theory about deep learning architectures can be found in [47, 48].
Manufacturing-derived training data for binary classification of quality poses the following challenges: (1) hyper-dimensional features spaces, including relevant, (2) highly/ultra unbalanced (minority/defective class count < 1%), irrelevant, trivial and redundant, (3) mix of numerical and categorical variables (i.e., nominal, ordinal or dichotomous), (4) different engineering scales, (5) incomplete data sets and (6) time dependent.
To address these challenges, the BM learning paradigm has been developed [16]. This paradigm is comprised of several well known ad-hoc tools plus many particular developments aimed at addressing specific challenges. Since the data structure is not known in advance, there is no a priori distinction between machine learning algorithms [49], therefore the BM learning paradigm suggests to explore eight diverse options to develop a multiple classifier system [40]. Due to the time effect, models are usually validated following a time-ordered hold-out scheme. The training set is partitioned in training, validation, and test sets, where the latest set is used to emulate deployment performance and compare it to the learning targets to demonstrate feasibility. Different data partitioning strategies can also be explored based on the data characteristics (see in [50]).
To induce information extraction and model trust, BM is founded on the principle of parsimony [51]. Parsimony is induced through feature selection [52] Footnote 2 and model selection [51]. These methods help to eliminate irrelevant, redundant and trivial features. To address the highly/ultra unbalanced problem, hyperparameters are tuned with respect to the Maximum Probability of Correct Decision [53], a metric based on the confusion metric highly sensitive to FN. Since most machine learning algorithms work internally with numeric data, it is important to develop a strategy to deal with categorical variables [54] (i.e., encode them in a numeric form). For binary features, it is recommended to use effect coding ( \(\) 1 and 1) instead of dummy coding (0 and 1) [55]. Moreover, since features tend to have different engineering scales, it is important to normalize or standardize the data before present it to the algorithm. Feature scaling generally speeds up learning and leads to faster convergence [56]. More insights about when to normalize or standardize can be found in [57, 58]. To deal with missing information, deleting rows or columns is a widely used approach; however, this method is not advised unless the proportion of eliminated records is very small ( \(
As reviewed in this subsection, developing a binary classifier using manufacturing-derived data is a complicated task. It is important to only select appropriate projects for the data science team. Selecting appropriate projects not only increases the likelihood of success, but also avoids unnecessary allocation of data science team resources. Moreover, developing a classifier with the capacity to satisfy the learning targets for the project (i.e., demonstrate feasibility), is just the beginning: higher order challenges must be understood and addressed to develop a sustainable solution that creates value to the company. The following section, provides deeper insights about these challenges.
In this section, four relevant issues posed by big data initiatives in manufacturing are discussed. These problems should be effectively addressed to increase the chances of success in the deployment of Quality 4.0. The following discussion frames the problems and takes place more from a philosophical perspective than from a technical perspective. In the context of these issues, an evolved problem solving strategy is proposed in “Problem solving strategy for a Quality 4.0 initiative” section.
Access to large amounts of data, increased computational power, and improvement of machine learning algorithms have contributed to the sharp rise of machine learning implementation in recent years. It is important, however, to discern whether and/or which AI techniques are appropriate for a given situation. This section will discuss some of the pitfalls and limitations of AI techniques, including low “understandability” and “trustability”. Much of the following will be discussed from a manufacturing perspective.
The big data approach conflicts with the pre-Industry 4.0 traditional philosophy, where models were developed and necessarily ground in physics-based theory. The inherent unknown nature of AI-based solutions, therefore, naturally leads to issues in trust, i.e., low “trustability.” Further contributing to the trustability issue is the fact that many machine learning techniques are black boxes, where the patterns used to classify a problem are not accessible or understandable. To a trained and practiced experimentalist, the inherent lack of a physics-based understanding can seem alarming. However, from a data scientist perspective, as long as the model can accurately predict unseen data, the model is validated.
The lack of understanding also causes problems from a root-cause standpoint. If machine learning-based models are to be used from a feedback control standpoint to identify “failures”, the inability to tie the model results with the physical system render it difficult to root-cause these failures and adjust the system parameters accordingly. Moreover, correlation does not imply causation, a feature predictive power does not necessarily imply in any way that that feature is actually related to or explains the underlying physics of the system being predicted.
It is a complicated task to attempt to understand these black box models [63], especially if the derived solution is based on a deep learning model. Though significant efforts are taking place to elucidate black box models [64,65,66], such efforts are still in their infancy. It is therefore recommended to determine, in advance, if a black box solution is an acceptable approach for a given application, with the caveat that little to no time should be expended in understanding the model.
In this context, it is sensible to approach a problem by starting with simpler models (e.g, support vector machine, naive Bayes, classification trees). Most of today’s problems can be more effectively solved by simple machine learning algorithms rather than deep learning [63]. Of course, deep learning is suitable in certain applications. For example, deep learning is well suited to image classification problems, where the resulting model does not need to be well understood, but if root cause analysis (or physics knowledge creation) is part of the project goals, creating features from images [44], followed by feature ranking and interpretation is a better approach.
The existence of a large amount of available data, smart algorithms, and computational power does not mean that the creation of a machine learning model is a value-add, nor is there necessarily even a straightforward machine learning solution. This is especially true in manufacturing, where systems are complex, dynamic, with many sources of variation (e.g., suppliers, environmental conditions, etc.). It is important to discern whether an machine learning model is even required by determining if it fits in one of the following problem types: (1) regression, (2) classification, (3) clustering, or (4) time-series. If the problem does not fall into one of those four categories, it is not a straightforward machine learning problem.
Even if machine learning is an appropriate approach for a given problem, an abundance of data does not necessarily imply that such data contains discriminative patterns or contains the intrinsic information required to accurately predict. A deep understanding of the process is therefore necessary to develop a customized solution. Developing such a solution is an iterative process, and it requires collaboration between the model developers and subject matter experts (engineers with domain knowledge).
In-lab solutions tend to be an overoptimistic representation of predictive system capabilities, since lab data is generated under highly controlled conditions. These conditions are likely not entirely representative of the plant environment. For this reason, lab-generated data is useful for developing proof-of-concept models; however, more work is required to increase the manufacturing readiness for plant deployment.
Many applications suffer from a scarcity of data. Lab data is often generated to develop prototype machine learning models. Been manually produced, the data is consequently often limited to hundreds (or in very fortunate cases, thousands) of samples. To perform hyperparameter tuning, these small data sets are used to create and test hundreds or even thousands of classifiers. Therefore, the chances of creating a spurious model that exhibits high prediction ability are very high [51]. But this model will never generalize beyond the training data.
As illustrated in the above text, AI techniques are powerful, but they are not a one-size-fits-all. Many intractable engineering problems are also AI-intractable. For this reason, project selection becomes an important problem and will be discussed in the following subsection.
A vision can be created, resources invested, teams formed, projects selected, yet there are many situations in which little to no value is obtained. Project selection drives the success of Quality 4.0. Today, the hype and success stories of AI have influenced most organizations to have an interest in deploying an AI initiative. But what is the current success rate? According to recent surveys, 80–87% of projects never make it into production [14, 15]. Improper project selection is the primary cause of this discouraging statistic, as many of these projects are ill-conditioned from the launch.
Whereas generic questions for choosing AI projects [67] and two dimensional feasibility approaches such as the pick chart (Fig. 5) from lean six sigma [68] and the machine learning feasibility assessment from Google Cloud [69] (Fig. 6) are useful and widely used [70], they do not to provide enough arguments to find the winners [71] in manufacturing applications.

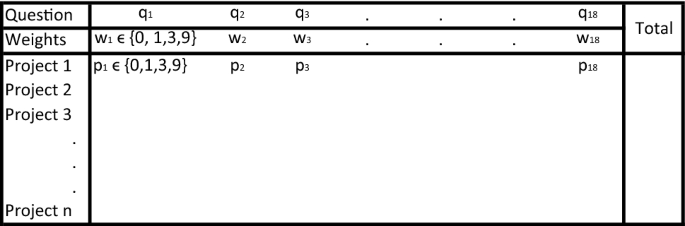
A strong project selection approach is founded on deep technical discussions, and business value analysis is required to develop a prioritized portfolio of projects. In this section, a list of 18 basic questions Footnote 3 aimed at evaluating each candidate project is presented.
These questions can be aggregated in a weighted decision matrix using the 0 (none), 1 (low), 3 (mid), 9 (most desirable condition) scoring system [72] to develop the data science portfolio of projects, Figs. 5, 7.
First projects should deliver value within a year. Therefore, even low rewarding “low hanging fruit” projects that may create business synergy and trust in these technologies are better starting points than highly rewarding “moon shots”. Projects with data already available can be a good place to start, since data generation is manual and time consuming.
If there is no in-house AI expertise, working with external partners is a good idea-while developing in-house expertise-to catch up with the pace of AI’s rise. However, the overoptimistic bias induced by vendors and the fallacy of planning should be avoided when selecting and defining a project.
It is important to keep in mind that data science projects are not independent from one other. To increase success likelihood, data science teams should be working on several projects concurrently. Once the first successful project is implemented, it will inspire new projects and ignite new ideas towards the development of the mid/long term visions. Companies with a well defined project selection strategy will be more likely to succeed in the era of Quality 4.0.
Machine learning algorithm are trained using observational data [73]. In contrast with experimental data that can be used for causal analysis, machine learning-derived information is ill conditioned for this task [63, 64, 74, 75], as discovered patterns may be spurious representations. To address this situation, the relevant features identified through data-driven methods (e.g., feature ranking/selection) should be used to extract information (e.g., uncover hidden patterns, associations, and correlations). This empirically-derived information, along with a physics analysis, can be used to generate useful hypotheses about possible connections between the features and the quality of the product. Then statistical analyses (e.g., randomized experiments) can be devised to establish causality to augment root-cause analyses and to find optimal parameters to redesign the process, as shown in Fig. 8. A real case study of this concept is presented in [10].
In machine learning, the concept of drift embodies the fact that the statistical distributions of the classes of which the model is trying to predict, change over time in unforeseen ways. This poses a serious technical challenges, as the classifiers assume a stationary relationship between features and classes. This static assumption is rarely satisfied in manufacturing. Consequently, the prediction capability of a trained model tends to significantly degrade overtime, resulting in friction, distrust, and a bad reputation for the data science teams. Although this concept has been widely studied [76, 77], in this section a few insights from manufacturing perspective are provided.
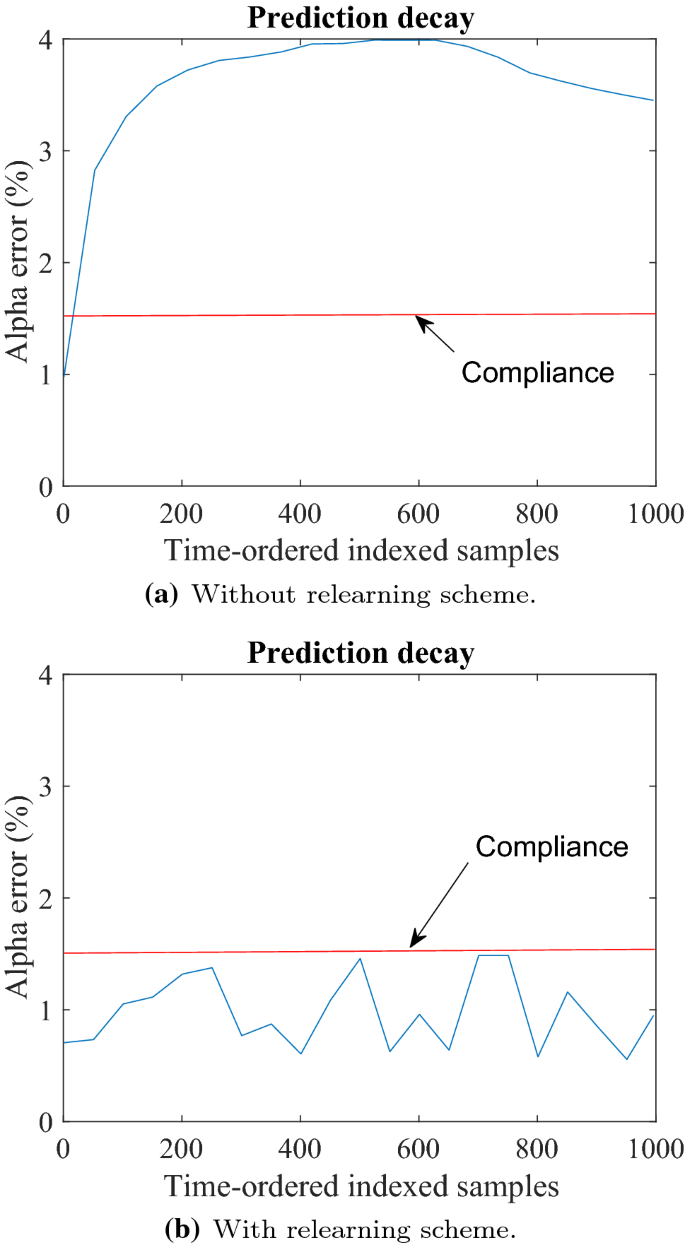
The transient and novel sources of variations cause manufacturing systems to exhibit non-stationary data distributions. Therefore, developing an in-lab model with the capacity to predict well the items in the test set and satisfy the learning targets for the project, is only the beginning since the model will usually degrade after deployment. In Fig. 9a, a real situation is presented, in which the model exhibited less than 1.5% of \(\alpha \) error (target set by the plant) in the test set (lab environment) to satisfy the defect detection goals ( \(\beta \) < 5 \(\%\) ) of the project. Immediately after deployment, the \(\alpha \) error increased to 1.78%. A few days later, the \(\alpha \) increased to 4%, an unacceptable FP rate for the plant. Although this model exhibited good prediction ability and made it into production, it was not a sustainable solution, and therefore never created value.
To put prediction decay into a binary classification context, it means that either or both \(\alpha \) or \(\beta \) errors increase to a problematic point. In the case of \(\alpha \) error, excessive FP generate the hidden factory effect (e.g., reducing process efficiency), whereas an increase of the \(\beta \) error, would generate more warranties, a less desirable situation.
The main goal of relearning, is to keep the predictive system in compliance with the restrictions set by the plant ( \(\alpha \) error), Fig. 9b, and the detection goals ( \(\beta \) error). This is accomplished by ensuring that the algorithm is learning the new statistical properties of both classes (good, defective). Continual learning or auto-adaptive learning is a fundamental concept in artificial intelligence that describes how the algorithms should autonomously learn and adapt in production as new data with new patterns comes in. Broadly speaking, a relearning scheme should include the following four components:
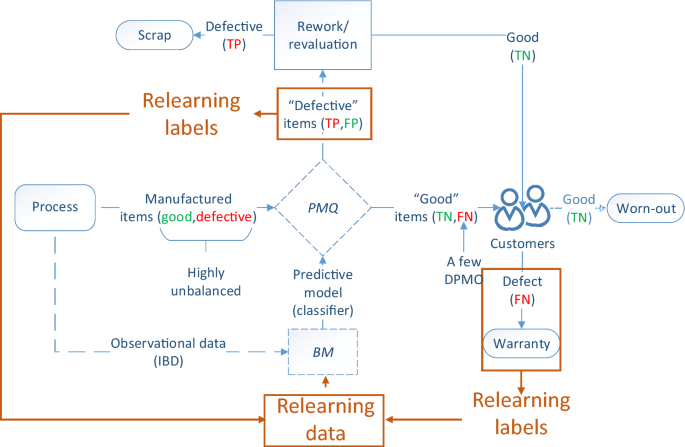
Other applications of machine learning tend to be more stable. For example, a neural network is trained to identify a stop sign. The stop sign will not change over time, and the algorithm can only improve with more data. This is not true for many manufacturing scenarios. To develop a sustainable solution, a relearning scheme should be developed before deployment that considers the type of drift the manufacturing system exhibits, e.g., temporal, gradual, recurring or sudden [78]. Although continual learning will ultimately optimize models for accuracy and save manual retraining time by making models auto-adaptive, even the more advance solutions would need the human supervision to ensure the predictive system is behaving as expected.
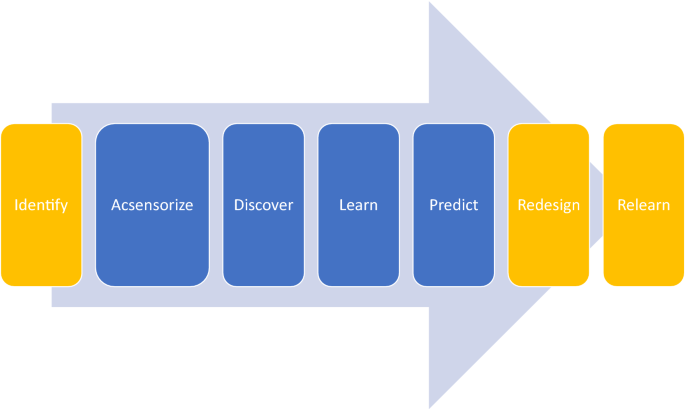
In the context of the issues presented in “Challenges of big data initiatives in manufacturing” section, an evolved problem solving strategy is presented to effectively implement AI in manufacturing. This evolved strategy is an update to the initial problem solving strategy—acsensorize, discover, learn, predict—proposed by PMQ [5]. Three more issues—identify, redesign, relearn—relevant to big data in manufacturing are included as extra steps to develop a comprehensive problem solving strategy for a successful implementation of a Quality 4.0 initiative, Fig. 12.
Since its introduction into the manufacturing world, the quality movement has continuously included new techniques, ideas, and philosophies from the various fields of engineering and science. Modern quality control can be traced back to the 1930’s when Dr. Walter Shewhart developed a new industrial SQC theory [79]. He proposed a 3-step problem solving strategy (specification, production, inspection—SPI) based on the scientific method. This problem solving method is known as the Shewhart learning and improvement cycle [80], Fig. 13a.
The TQM philosophy emerged in the 1980’s [81], where the Shewhart’s problem solving strategy was refined by Deming, also known as the Deming cycle, Fig. 13b, to develop a more comprehensive problem solving approach (plan, do, check/study, act,—PDCA or PDSA).
A few years later, in 1986, six sigma was introduced by Bill Smith at Motorola. Six sigma is a reactive approach, based on a 5-step problem solving strategy (define, measure, analyze, improve, control—DMAIC) aimed at identifying and eliminating the causes of defects and/or sources of variation from processes. Its complement Design for Six Sigma (DFSS) appeared shortly after, a proactive approach aimed at designing robust products and processes so that defects are never generated, Fig. 13d, [82, 83]. It is founded on optimization techniques which are usually applied through a 6-step problem solving strategy (define, measure, analyze, design, optimize, verify—DMADOV).
To cope with the ever increasing complexity of manufacturing systems, each new quality philosophy has redefined the problem solving strategy. It started with a basic 3-step approach and has gradually evolved and increased its complexity up-to the 7-step approach (identify, acsensorize, discover, learn, predict, redesign, relearn— \(IADLPR^\) ) herein proposed, Fig. 13.
Manufacturing systems pose particular intellectual and practical challenges (e.g., cycle times, transient sources of variation, reduced lifetime, high conformance rates, physics-based) that must be effectively addressed to create value out of IBD. The \(IADLPR^2\) problem solving strategy is founded on theory and our knowledge studying complex manufacturing systems. According to empirical results, this new problem solving strategy should increase the chances of successfully deploying a Quality 4.0 initiative.
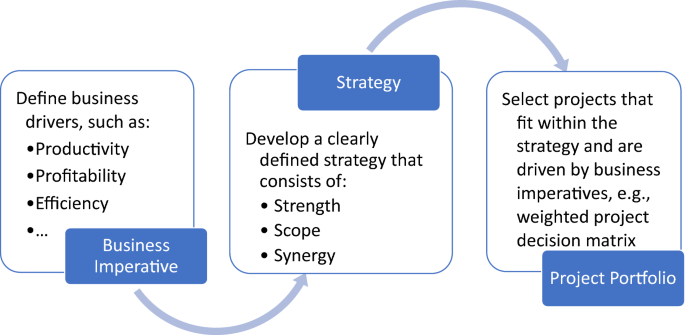
Adopting a new philosophy will inevitably suffer from resistance. Broadly, this resistance to adoption falls into three categories: psychological reservations, infrastructural limitations, and business impediments. A strategic vision for adopting the Quality 4.0 philosophy can help mitigate against this. The strategy should be developed and driven by business imperatives, and should be used to create a project portfolio. Any successful strategy should comprise strength, scope, and synergy. Strength defines the competitive advantage, i.e., what makes the company “stand out” from the rest. Scope encompasses not only what the company should do, but what they choose not to do. Finally, synergy ensures that all parts work together in support of the overall vision, i.e., there are no contradictory practices. Figure 14 contains a map for strategy development and adoption of Quality 4.0. In this section, some of the considerations that should be taken into account when developing/adopting such a strategic vision will be discussed. In the interest of brevity, this discussion will be kept short. The reader is referred to Porter [84], Cheatham et. al [85], Kotter [86], Bughin [87], and Davenport and Ronanki [88] for more detailed discussions on AI and strategy.
Having the appropriate infrastructure is crucial to the ability to adopt Quality 4.0 practices. Quality 4.0 practices require a fully connected lab/production environment to enable data acquisition and analysis. IT should support and enable any updates required while ensuring that adequate security and access polices are adopted. Adequate infrastructure should exist for data storage, computation, and deployment (to enable scaled-up solutions). Ultimately, for a new vision to be successfully adopted, the company culture must accept it. For this reason, it is important that the philosophy is advocated for and supported by management. It can help the overall attitude to locally implement relevant aspects of Quality 4.0 practices, i.e., not all at once. Local successes can promote positive attitudes towards adoption.
Companies should perform a risk-benefit analysis, such as projections on investments versus the benefits of developing Quality 4.0 capabilities. Since AI in manufacturing is in an early stage, there is no guarantee of return-on-investment (at least in the short term). The company therefore may need to incorporate this analysis into budget planning to determine if deployment of Quality 4.0 resources (e.g., staff, hardware and software) is possible. Once the company culture, infrastructure, and business conditions allow for adopting a Quality 4.0 strategy, successful deployment should consist of cross-functional teams. Cross-functional teams enable the successful execution of Quality 4.0 projects. For example, management should select impactful projects. In house data science expertise should exist (although this can be complemented with some consulting work too). Data science teams should confirm that the projects that are actually machine learning projects (i.e., fit within the scope of Quality 4.0 paradigm). Management and IT should coordinate with plant teams to ensure proper collection of data. IT should facilitate projects by ensuring collected data is available for analysis and the solution scaled and deployed. Finally, engineers and subject matter experts should confirm that the solution satisfies the engineering requirements and that the model is trustable (i.e., it captures the underlying physics of the process).
The hype surrounding artificial intelligence and big data have propelled an interest by many quality leaders to deploy this technology in their companies. According to recent surveys, however, 80–87% of these projects never develop a production-ready sustainable solution and many of these leaders do not have a clear vision of how to implement Quality 4.0 practices. In this article, four big data challenges in manufacturing are discussed: the change in paradigm, the project selection problem, the process redesign problem, and the relearning problem. These challenges that must be fully understood and addressed to enable the successful deployment of Quality 4.0 initiatives in the context of Process Monitoring for Quality. Based on this study, a novel 7-step problem solving strategy (identify, acsensorize, discover, learn, predict, redesign, relearn) is proposed. This comprehensive approach increases the likelihood of success.
The importance of developing and adopting a Quality 4.0 strategy is also discussed. A well defined strategy ensures that business imperatives are met, mitigates against resistance to adoption, and enables the appropriate selection of projects.
Future research should focus on evaluating project potential via the 18 questions herein presented in order to describe the characteristics associated at each level, i.e., none, low, mid and desirable. This would increase the effectiveness of using the weighted project selection matrix to rank (prioritize) projects. This work can also be extended by redefining the problem solving strategy based on deep learning, as the discovered step (i.e, future creation/engineering) is not required.

